

What is Text Analysis?
Text analysis is the process of automatically classifying and extracting information from unstructured text.
Machine Learning can work with different types of textual information such as social media posts (Twitter, Facebook, YouTube), messages, emails etc.
How does machine learning text analysis work?
Data Mining —-> Data pre-processing —-> Applying ML algorithms for analysis
What do you need to build up a text analysis tool?
Here are the steps that you need to follow,
- Data Gathering – Decide on what information that you need to do the text analysis and how you will collect those text data.
- Data Preparation – Gathered data needs to be pre-processed, such that all the meaningless texts are prepared in a structured way.
- Application of machine learning algorithms for text analysis – Several machine learning algorithms can be applied and choose the best fitting algorithm.
The techniques that we use in text analysis.
- Tokenization
It is a most common task when it comes to textual data. Tokenization is essentially splitting a sentence, phrase, paragraph or text document into smaller units such as words or terms. Each of these smaller units are called tokens. For example,
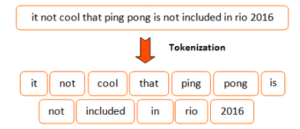
- Part of Speech Tagging
PoS Tagging is identifying each tokens part of speech such as noun, adverb, adjective and then tagging it as such. Below is the specific part of speech tags.
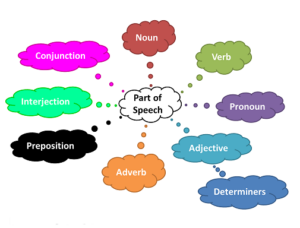
For example, in the sentence ‘I want an upgrade‘, Here I refer to Pronoun, want refers to a verb, a refers to determiners and upgrade refers to a noun
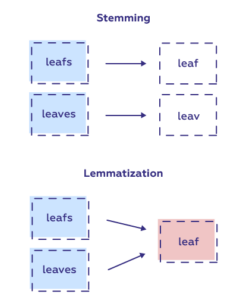
- Stemming and Lemmatization
Stemming is a method of normalization of words in Natural Language Processing. Here, a set of words in a sentence are converted into a sequence to shorten its lookup. The words having the same meaning, but have some variations according to the sentence are normalized.
For example, the root word is ‘eat’ and its variations are ‘eats, eating, eaten’. Likewise stemming in python helps to find the root word of any variations.
Example:
- He was riding
- He was taking the riding
Here both sentences are the same meaning, so stemming is used to categorize the same type of data by getting its root word.
Lemmatization is closely related to stemming. It is returning different forms of a single word to its root form.
Example:
- Constructing – (Lemmatization) – > Construct
- Extracts – (Lemmatization) -> Extract
- Singing – (lemmatization) – > Sing
Application of machine learning algorithms for text analysis
Machine learning-based systems can make predictions based on what they learn from past observations. So that the training data has to be transformed into something a machine can understand. That means all the texts must convert into vectors which is a list of numbers.
These vectors can extract features of the text and help it learn from the existing data and make predictions about the texts to come.
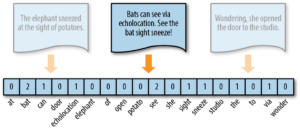
Text vectorization can be done using a bag of words vectorizations, TFIDF vectorization and count vectorization. Once texts are transformed into vectors, they are fed into a machine-learning algorithm together with their expected output to create a classification model.
It can choose the best features of a text and make predictions about unseen texts.
Practical Applications of ML Text Analysis
- Social Media Monitoring
- Sales and marketing
- Customer service
- Robotics
- NLP systems for chatbots, smart assistants