

In the real world, we are awash in images. Mainly, images are generated from smartphones which have their cameras. In daily, mind-blogging amounts of data are generated in different ways. There are many great problems that can be identified and solved with the use of image data.
In this context, computer vision is utmost important and a kind of challenging field. To obtain the most out of image data, we want computers to see an image and understand its content. This is a trivial problem for a human. A normal person can explain the content of an image once they have seen it. Also, a person can recognize/categorize an image as a human or an animal or other once they have seen it. Accordingly, we require at least the same capabilities from computers to unlock our images.
What is Computer Vision?
Computer vision is a multidisciplinary field that can broadly be a sub-field of Artificial Intelligence (AI) and Machine Learning (ML). It mainly uses some specialized methods and algorithms as well as developing methods in order to reproduce the capability of a human.
Also, with the image data, a variety of computer vision applications in various domains is being developed to ease the human daily work process. In this article, I would explain some applications in computer vision with the technologies used.
Optical Character Recognition
Optical Character Recognition (OCR) is a technology that enables us to extract text characters from scanned images of printed or handwritten documents. It has many applications for the processing of handwritten forms, bank statements, electronic health, insurance, logistics and legal documentation and also a variety of PDF documents generated by businesses.
OpenCV is a python library and its new EAST text detector is useful for detecting the presence of text in natural scene images. This text detector is accurate and is capable of running in near real-time at approximately 13 FPS on 720p images.
By using Open CV EAST deep learning model, we can detect and localize the bounding box coordinates of the text contained in an image. To recognize the detected texts, Tesseract python library can be used. Tesseract is a highly popular OCR engine and it was originally developed by Hewlett Packard in the 1980s and was then open-sourced in 2005. The latest release of Tesseract (v4) has included a highly accurate deep learning-based model for text recognition rather than traditional feature extraction and machine learning approaches.

Image Classification
In computer vision, image classification plays an important role in a variety of domains such as Agriculture, Medicine, Pharmaceutical and Geography. Also, image classification is a process of predicting a specific class or label of an image with the use of groups of pixels or vectors within the image based on specific rules. Following are some useful image classification applications derived from the field of computer vision.
a) Face Recognition
Example: Social Media; Snapchat and Facebook use face-detection algorithms to recognize your images or images of friends in your network.

b) Disease Recognition
Example: Malaria recognition using blood smear images

c) Drug Identification
Example: Drug identification model for images of specific drugs used by chronic patients. This type of system is useful for effectively reducing the problem of drug interactions caused by taking incorrect drugs.

d) Plant Recognition
Example: Plant identification is mainly applied in fields of medicine, botany and food. Images based Tomato Leaves Diseases Detection

e) Surveillance
Example: Surveillance cameras are always seen at public locations and are used to detect suspicious behaviours.

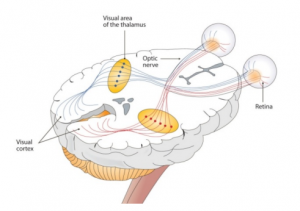
Convolutional Neural Network (CNN) is a promising deep learning model which can be used for solving the aforementioned image classification problems. When considering the architecture of a CNN, it is similar to the connectivity pattern of Neurons in a Human Brain. Also, CNN’s mainly follow the biological inspiration from the visual cortex which has small regions of cells that are sensitive to specific regions of the visual field. As an example, some neurons fired when exposed to vertical edges as well as horizontal or diagonal edges. Accordingly, the concept behind CNN is the capability of looking at the specific characteristics with its neuronal cells in the visual cortex.
There are various standard CNN model architectures. Few of them are LeNet, AlexNet, VGGNet, GoogLeNet and ResNet. Also, CNN models can be developed using python language with Keras or Tensorflow. Keras is an open-source deep-learning library written in Python. Tensorflow is a python library that can be used to create deep learning models directly or by using wrapper libraries that simplify the process built on top of TensorFlow.

f) Comparing two images
Example: For Signature verification: Two signatures are needed to be compared to determine whether one is a forgery or not.

Comparing images for similarity, Siamese networks with Keras, and TensorFlow can be used. Siamese networks are an artificial neural network which mainly consists of two Convolutional Neural Networks. Hence, the name Siamese Networks is given to this network.
Computer Vision Pros and Cons
Computer vision is mainly capable of providing faster and simpler process and also providing accurate predictions and reducing cost, time for specific tasks which are manually done by humans. When considering the Cons, for training a computer vision system using ML or AI, a team of professionals with technical expertise is required for continuous monitoring.
Presently, amazing feats by AI with computer vision technology is increasing in a variety of industrial fields. In future, computer vision technology would be a great benefit for human beings for getting incredible and Eco-friendly outcomes.