
Let’s take a look at the call stack in Node JS. This article will be focusing on the below :
- What is Call Stack?
- Why is that important?
- Where can we use it?
If you are a developer or an IT student, I have no doubt, you might have heard this word called “STACK”. This is constantly used in data structures and algorithms. When it comes to application development, the same concept is used in data structures and algorithms. Let’s talk about this further.
What is Call Stack?
In simple terms, it is a mechanism that is used by an interpreter (like javascript/python) to manage the script execution and keep tracking which function is currently being run.
Let’s go in a bit deeper,
Note this, the call stack mechanism is based on the LIFO (Last In First Out) principle like the stack in DSA (data structures and algorithm). When the program starts to execute then the script calls the function. At this time the interpreter adds that function to the top of the call stack and carries out the function body. Once the current function completes its executions, that function is popped off from the stack by the javascript engine. This process gets a little bit complex when it comes to the Web API level execution. In a situation like this, we have to learn about “call back queue” and “event loop” to understand the non-blocking (Asynchronous) execution of the program.
You will get a clearer idea about this mechanism when we look into simple examples. Before that, you will have to know the following things.
Why should you learn about this?
When you are going to develop a web application, you have to learn about functions, APIs, layers etc. Also, we must be focused on the performance of our application. For that, we must have knowledge on “call stack”. That is one of the super options that we can improve the performance of the application.
Another great thing about call stack is that each ‘call stack’ can have its own separate stack since different functions are doing different things and also call stack supports simultaneous calls till the program is terminated.
Let’s get an idea using a simple example,
Step 01: explain the code snippet.
Step 02: explain the code snippet with the call stack.
Step 01: Program explanation.
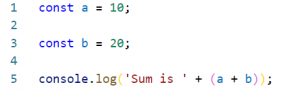
Figure 1: program for print a plus b.
- Line number 1 – “10” is assigned to “a”.
- Line number 3 – “20” is assigned to “b”.
- Line number 5 – print the sum of “a” plus “b”.
Step 02: Explain code snippet with the call stack.
You already know that when a program calls a function, the interpreter adds that function to the top of the call stack. Let’s see what takes place behind this.
- At first, the code snippet will wrap the main function which is provided by the Node JS. The main function is pushed on to the call stack all the way to the bottom since there is nothing else in the stack.

Figure 2: add the main function into the call stack.
- When line number five is executed, the log function is added to the top of the call stack as it is a function. As given below, now there are two functions inside the call stack.

Figure 3: add log function into the call stack.
- Once the log function is added to the call stack, it will start its job which is to print the sum of “a” and “b” on the console. As you can see below, the log function will be printed as the sum of “a” and “b”.

Figure 4: print sum of a and b.
- As you already know, once a function has completed its job, that function will be popped off from the call stack.
- Since this mechanism always refers to the LIFO principle, the log function will be popped off from the call stack that is last inserted and has completed its job as well.
- Next, the main function will also get popped off from the call stack since there are no more functions to be executed.

Figure 5: pop off log and main functions from the call stack.
Here is another example that shows call stack, API and callback queue mechanisms all together.
Step 1: Explanation.
Step 2: Call stack, Node APIs, callback queue and event loop mechanism.

Figure 6: asynchronous program.
Step 01: Explanation.
In this code snippet, we will be using call stack along with Node AIPs, callback queue and event loop. Now let’s see what happens behind this code. Firstly, the main function will be added to the call stack and then the “program started” string will be printed on the console and the function will be removed from the stack. Next, the setTimeout* function will be called which must wait for one second to be executed.
Step 02: Call stack, API, callback queue and event loop mechanism.
In order to wait for one second setTimeout function gets registered in Node APIs. Although the setTimeout function waits for one second to be executed, the program will not wait for a second.
As given below Call stack will continue the program by calling the next Log function. Then the “mid of the program” text will print on the console and the log function is popped out from the call stack as it is completed. This is the non-blocking (asynchronous) nature of the Node.
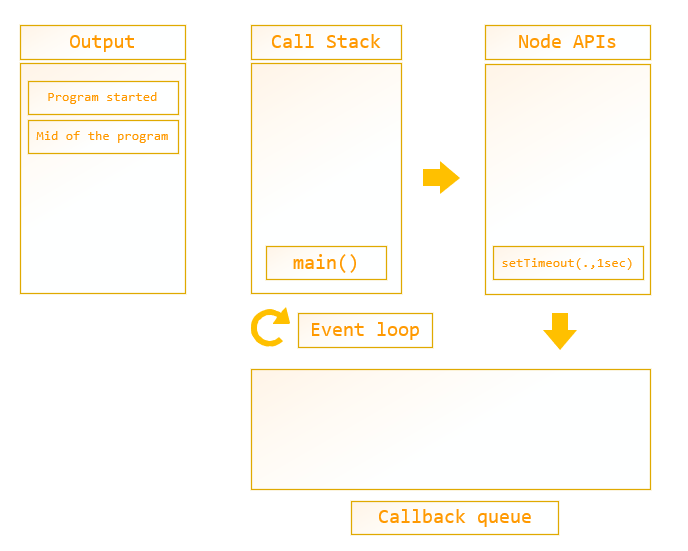
Figure 7: call stack mechanism – asynchronous nature
As you can see, the second setTimeout function starts from the ninth line. That function also goes through the same process as the first setTimeout function. Now, as you can see, both setTimeOut functions are registered in Node APIs.
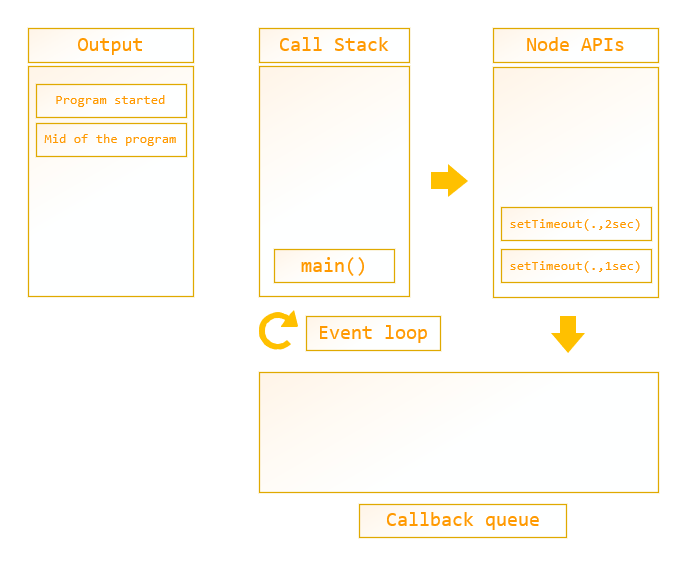
Figure 8: call stack mechanism – API register
One thing needs to be noted, as a single-threaded language, javascript does one thing at a time which means call stack can only do one thing at a time.
As the next step of the execution, the setTimeout (with 1 second) function gets added to the callback queue. In this situation, the event loop has to check the call stack and callback queue. If the call stack is empty then the callback function will be added on the call stack and execute the function.
By the way, “program ended” will be printed on the console when the last log function is executed by the call stack since the main function is still on the call stack. Then it will be popped off from the stack and the main function also gets off from the call stack.
As you can see below, the first setTimeout function is waiting to be added to the call stack and the other one is in Node APIs.
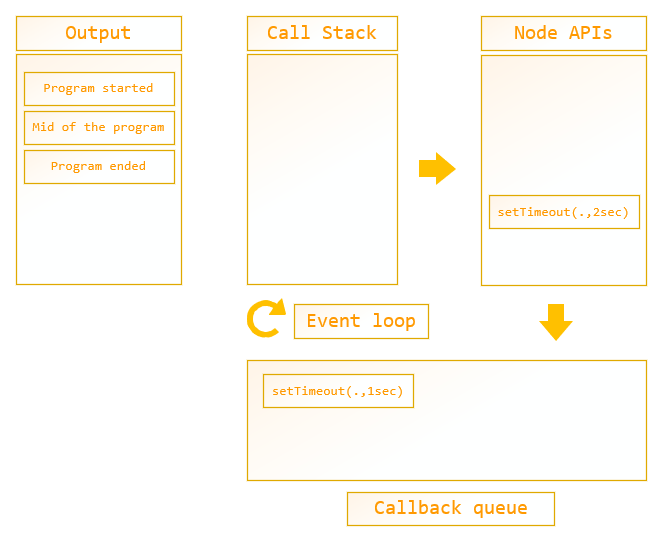
Figure 9: call stack mechanism – callback queue
As the next steps of the code, the setTimeout function gets added to the call stack since it is empty now. “1 second left” string will be printed on the console as the output of the first setTimeout function.
Next, the setTimeout function also gets added to the callback queue and it will be added to the call stack by the event loop since the call stack is empty. “2 seconds left” string will be printed on the console as the output of the second setTimeout function and the function will be removed from the stack.
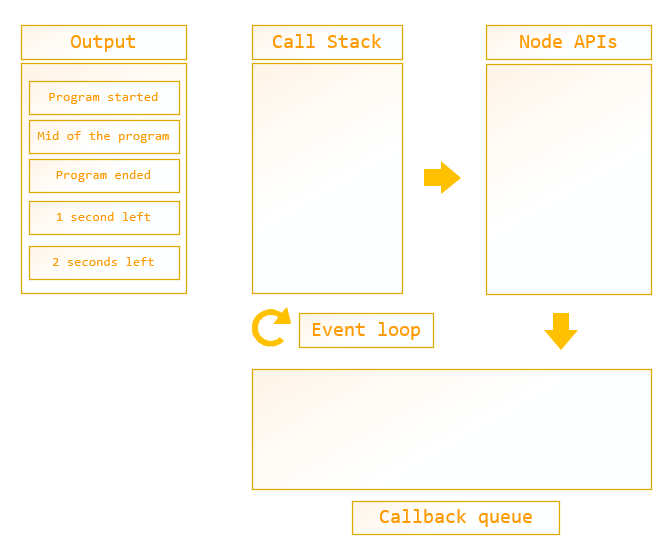
Figure 10: call stack mechanism – program output
Watch the below video to get a better idea of the process.
* This function is not a javascript function and the V8 engine has not been implemented for this function. It is a function implemented in C++ and provides a Node JS script to use.
Thank you.




